1.数据流转——Flink的数据抽象及数据交换过程
1.1 MemorySegment
Flink作为一个高效的流框架,为了避免JVM的固有缺陷(java对象存储密度低,FGC影响吞吐和响应等),必然走上自主管理内存的道路。
这个MemorySegment就是Flink的内存抽象。默认情况下,一个MemorySegment可以被看做是一个32kb大的内存块的抽象。这块内存既可以是JVM里的一个byte[],也可以是堆外内存(DirectByteBuffer)。
如果说byte[]数组和direct memory是最底层的存储,那么memorysegment就是在其上覆盖的一层统一抽象。它定义了一系列抽象方法,用于控制和底层内存的交互,如:
1 | public abstract class MemorySegment { |
我们可以看到,它在提供了诸多直接操作内存的方法外,还提供了一个wrap()方法,将自己包装成一个ByteBuffer,我们待会儿讲这个ByteBuffer。
Flink为MemorySegment提供了两个实现类:HeapMemorySegment和HybridMemorySegment。他们的区别在于前者只能分配堆内存,而后者能用来分配堆内和堆外内存。事实上,Flink框架里,只使用了后者。这是为什么呢?
如果HybridMemorySegment只能用于分配堆外内存的话,似乎更合常理。但是在JVM的世界中,如果一个方法是一个虚方法,那么每次调用时,JVM都要花时间去确定调用的到底是哪个子类实现的该虚方法(方法重写机制,不明白的去看JVM的invokeVirtual指令),也就意味着每次都要去翻方法表;而如果该方法虽然是个虚方法,但实际上整个JVM里只有一个实现(就是说只加载了一个子类进来),那么JVM会很聪明的把它去虚化处理,这样就不用每次调用方法时去找方法表了,能够大大提升性能。但是只分配堆内或者堆外内存不能满足我们的需要,所以就出现了HybridMemorySegment同时可以分配两种内存的设计。
我们可以看看HybridMemorySegment的构造代码:
1 | HybridMemorySegment(ByteBuffer buffer, Object owner) { |
其中,第一个构造函数的checkBufferAndGetAddress()方法能够得到direct buffer的内存地址,因此可以操作堆外内存。
1.2 ByteBuffer与NetworkBufferPool
在MemorySegment这个抽象之上,Flink在数据从operator内的数据对象在向TaskManager上转移,预备被发给下个节点的过程中,使用的抽象或者说内存对象是Buffer。
注意:这个Buffer是个Flink接口,不是java.nio提供的那个Buffer抽象类。Flink在这一层面同时使用了这两个同名概念,用来存储对象,直接看代码时到处都是各种xxxBuffer很容易混淆:
- java提供的那个Buffer抽象类在这一层主要用于构建HeapByteBuffer,这个主要是当数据从jvm里的一个对象被序列化成字节数组时用的;
- Flink的这个Buffer接口主要是一种Flink层面用于传输数据和事件的统一抽象,其实现类是NetworkBuffer,是对MemorySegment的包装。Flink在各个TaskManager之间传递数据时,使用的是这一层的抽象。
因为Buffer的底层是MemorySegment,这可能不是JVM所管理的,所以为了知道什么时候一个Buffer用完了可以回收,Flink引入了引用计数的概念,当确认这个buffer没有人引用,就可以回收这一片MemorySegment用于别的地方了(JVM的垃圾回收为啥不用引用计数?读者思考一下):
1 | public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf { |
为了方便管理NetworkBuffer,Flink提供了BufferPoolFactory,并且提供了唯一实现NetworkBufferPool,这是个工厂模式的应用。
NetworkBufferPool在每个TaskManager上只有一个,负责所有子task的内存管理。其实例化时就会尝试获取所有可由它管理的内存(对于堆内存来说,直接获取所有内存并放入老年代,并令用户对象只在新生代存活,可以极大程度的减少Full GC),我们看看其构造方法:
1 | public NetworkBufferPool(int numberOfSegmentsToAllocate, int segmentSize) { |
由于NetworkBufferPool只是个工厂,实际的内存池是LocalBufferPool。每个TaskManager都只有一个NetworkBufferPool工厂,但是上面运行的每个task都要有一个和其他task隔离的LocalBufferPool池,这从逻辑上很好理解。另外,NetworkBufferPool会计算自己所拥有的所有内存分片数,在分配新的内存池时对每个内存池应该占有的内存分片数重分配,步骤是:
- 首先,从整个工厂管理的内存片中拿出所有的内存池所需要的最少Buffer数目总和
- 如果正好分配完,就结束
- 其次,把所有的剩下的没分配的内存片,按照每个LocalBufferPool内存池的剩余想要容量大小进行按比例分配
- 剩余想要容量大小是这么个东西:如果该内存池至少需要3个buffer,最大需要10个buffer,那么它的剩余想要容量就是7
实现代码如下:
1 | private void redistributeBuffers() throws IOException { |
接下来说说这个LocalBufferPool内存池。
LocalBufferPool的逻辑想想无非是增删改查,值得说的是其fields:
1 | /** 该内存池需要的最少内存片数目*/ |
承接NetworkBufferPool的重分配方法,我们来看看LocalBufferPool的setNumBuffers方法,代码很短,逻辑也相当简单,就不展开说了:
1 | public void setNumBuffers(int numBuffers) throws IOException { |
1.3 RecordWriter与Record
我们接着往高层抽象走,刚刚提到了最底层内存抽象是MemorySegment,用于数据传输的是Buffer,那么,承上启下对接从Java对象转为Buffer的中间对象是什么呢?是StreamRecord。
从StreamRecord
那么这个对象是怎么变成LocalBufferPool内存池里的一个大号字节数组的呢?借助了StreamWriter这个类。
我们直接来看把数据序列化交出去的方法:
1 | private void sendToTarget(T record, int targetChannel) throws IOException, InterruptedException { |
先说最后一行,如果配置为flushAlways,那么会立刻把元素发送出去,但是这样吞吐量会下降;Flink的默认设置其实也不是一个元素一个元素的发送,是单独起了一个线程,每隔固定时间flush一次所有channel,较真起来也算是mini batch了。
再说序列化那一句:
1 | SerializationResult result = serializer.addRecord(record); |
在这行代码中,Flink把对象调用该对象所属的序列化器序列化为字节数组。
1.4 数据流转过程
上一节讲了各层数据的抽象,这一节讲讲数据在各个task之间exchange的过程。
1.4.1 整体过程
看这张图: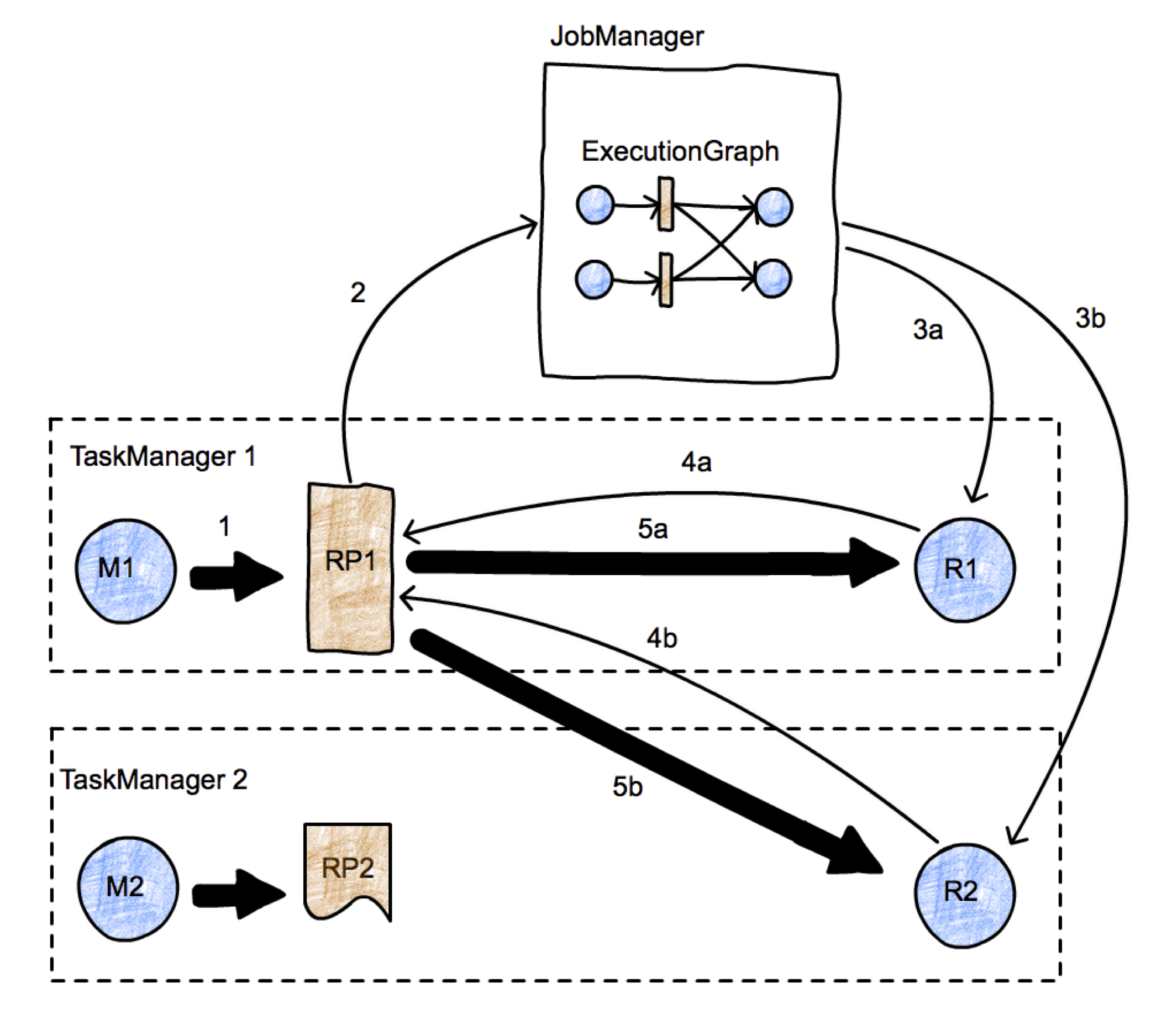
- 第一步必然是准备一个ResultPartition;
- 通知JobMaster;
- JobMaster通知下游节点;如果下游节点尚未部署,则部署之;
- 下游节点向上游请求数据
- 开始传输数据
1.4.2 数据跨task传递
本节讲一下算子之间具体的数据传输过程。也先上一张图: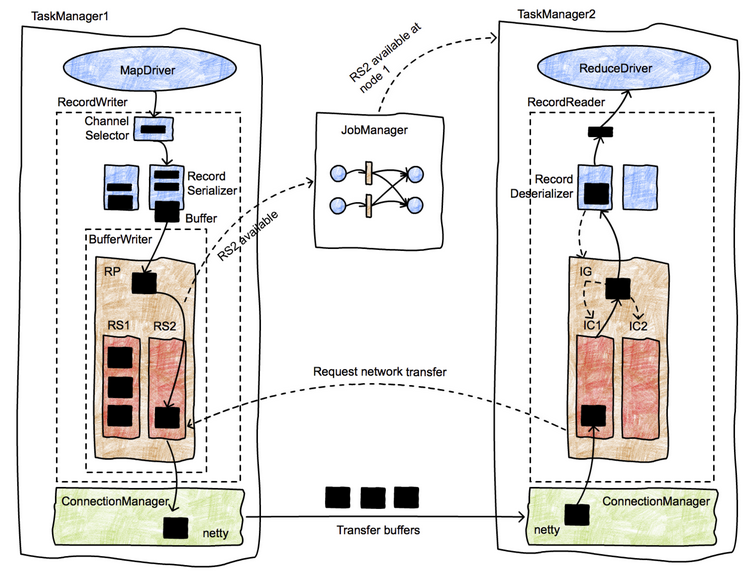
数据在task之间传递有如下几步:
- 数据在本operator处理完后,交给RecordWriter。每条记录都要选择一个下游节点,所以要经过ChannelSelector。
- 每个channel都有一个serializer(我认为这应该是为了避免多线程写的麻烦),把这条Record序列化为ByteBuffer
- 接下来数据被写入ResultPartition下的各个subPartition里,此时该数据已经存入DirectBuffer(MemorySegment)
- 单独的线程控制数据的flush速度,一旦触发flush,则通过Netty的nio通道向对端写入
- 对端的netty client接收到数据,decode出来,把数据拷贝到buffer里,然后通知InputChannel
- 有可用的数据时,下游算子从阻塞醒来,从InputChannel取出buffer,再解序列化成record,交给算子执行用户代码
数据在不同机器的算子之间传递的步骤就是以上这些。
了解了步骤之后,再来看一下部分关键代码:
首先是把数据交给recordwriter。
1 | //RecordWriterOutput.java |
然后recordwriter把数据发送到对应的通道。
1 | //RecordWriter.java |
接下来是把数据推给底层设施(netty)的过程:
1 | //ResultPartition.java |
netty相关的部分:
1 | //AbstractChannelHandlerContext.java |
最后真实的写入:
1 | //PartittionRequesetQueue.java |
上面这段代码里第二个方法中调用的writeAndFlush就是真正往netty的nio通道里写入的地方了。在这里,写入的是一个RemoteInputChannel,对应的就是下游节点的InputGate的channels。
有写就有读,nio通道的另一端需要读入buffer,代码如下:
1 | //CreditBasedPartitionRequestClientHandler.java |
插一句,Flink其实做阻塞和获取数据的方式非常自然,利用了生产者和消费者模型,当获取不到数据时,消费者自然阻塞;当数据被加入队列,消费者被notify。Flink的背压机制也是借此实现。
然后在这里又反序列化成StreamRecord:
1 | //StreamElementSerializer.java |
然后再次在StreamInputProcessor.processInput循环中得到处理。
至此,数据在跨jvm的节点之间的流转过程就讲完了。
2 Credit漫谈
2.1 背压问题
在流模型中,我们期待数据是像水流一样平滑的流过我们的引擎,但现实生活不会这么美好。数据的上游可能因为各种原因数据量暴增,远远超出了下游的瞬时处理能力(回忆一下98年大洪水),导致系统崩溃。
那么框架应该怎么应对呢?和人类处理自然灾害的方式类似,我们修建了三峡大坝,当洪水来临时把大量的水囤积在大坝里;对于Flink来说,就是在数据的接收端和发送端放置了缓存池,用以缓冲数据,并且设置闸门阻止数据向下流。
那么Flink又是如何处理背压的呢?答案也是靠这些缓冲池。
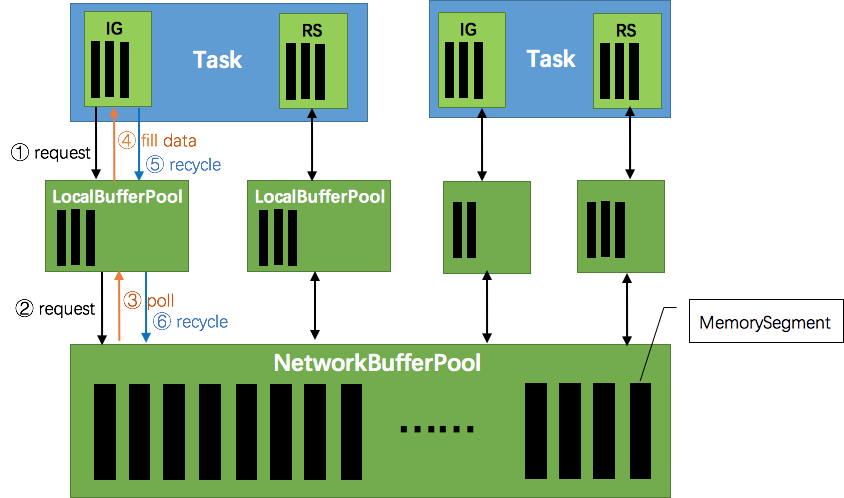
这张图说明了Flink在生产和消费数据时的大致情况。ResultPartition和InputGate在输出和输入数据时,都要向NetworkBufferPool申请一块MemorySegment作为缓存池。
接下来的情况和生产者消费者很类似。当数据发送太多,下游处理不过来了,那么首先InputChannel会被填满,然后是InputChannel能申请到的内存达到最大,于是下游停止读取数据,上游负责发送数据的nettyServer会得到响应,停止从ResultSubPartition读取缓存,那么ResultPartition很快也将存满数据不能被消费,从而生产数据的逻辑被阻塞在获取新buffer上,非常自然地形成背压的效果。
Flink自己做了个试验用以说明这个机制的效果: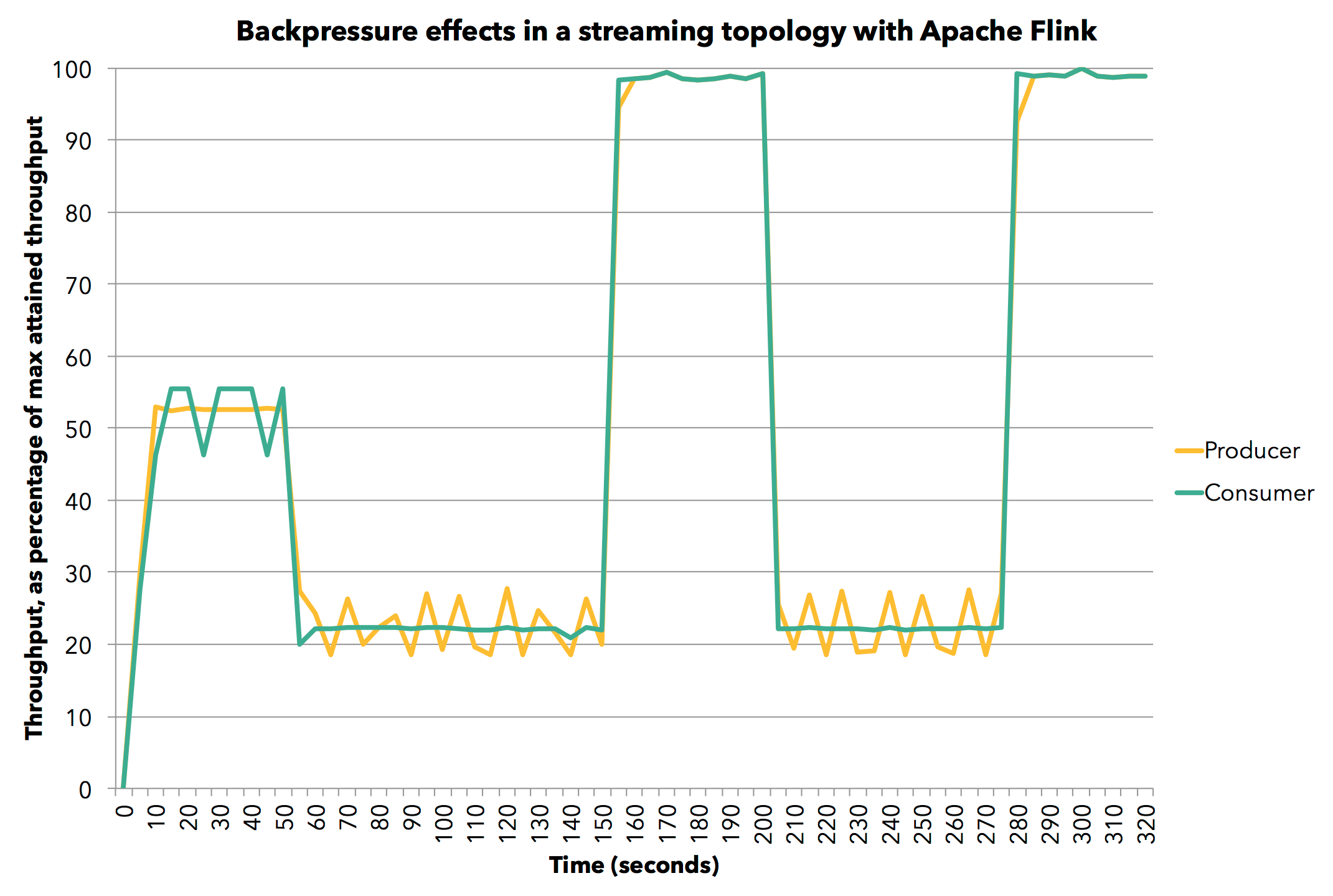
我们首先设置生产者的发送速度为60%,然后下游的算子以同样的速度处理数据。然后我们将下游算子的处理速度降低到30%,可以看到上游的生产者的数据产生曲线几乎与消费者同步下滑。而后当我们解除限速,整个流的速度立刻提高到了100%。
2.2 使用Credit实现ATM网络流控
上文已经提到,对于流量控制,一个朴素的思路就是在长江上建三峡链路上建立一个拦截的dam,如下图所示: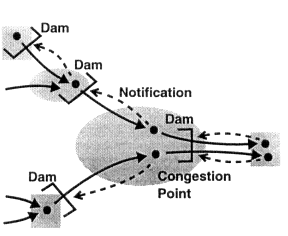
基于Credit的流控就是这样一种建立在信用(消费数据的能力)上的,面向每个虚链路(而非端到端的)流模型,如下图所示: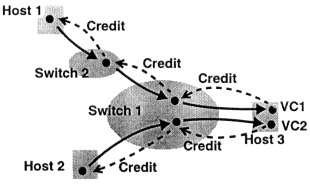
首先,下游会向上游发送一条credit message,用以通知其目前的信用(可联想信用卡的可用额度),然后上游会根据这个信用消息来决定向下游发送多少数据。当上游把数据发送给下游时,它就从下游的信用卡上划走相应的额度(credit balance):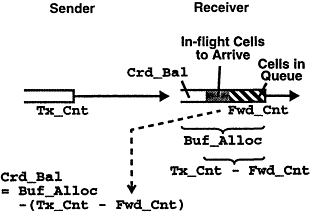
下游总共获得的credit数目是Buf_Alloc,已经消费的数据是Fwd_Cnt,上游发送出来的数据是Tx_Cnt,那么剩下的那部分就是Crd_Bal:
Crd_Bal = Buf_Alloc - ( Tx_Cnt - Fwd_Cnt )
上面这个式子应该很好理解。
可以看到,Credit Based Flow Control的关键是buffer分配。这种分配可以在数据的发送端完成,也可以在接收端完成。对于下游可能有多个上游节点的情况(比如Flink),使用接收端的credit分配更加合理: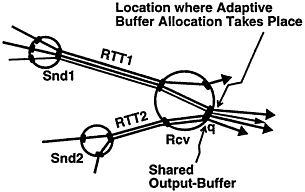
上图中,接收者可以观察到每个上游连接的带宽情况,而上游的节点Snd1却不可能轻易知道发往同一个下游节点的其他Snd2的带宽情况,从而如果在上游控制流量将会很困难,而在下游控制流量将会很方便。
因此,这就是为何Flink在接收端有一个基于Credit的Client,而不是在发送端有一个CreditServer的原因。
最后,再讲一下Credit的面向虚链路的流设计和端到端的流设计的区别: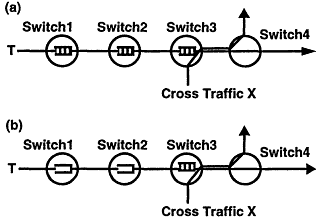
如上图所示,a是面向连接的流设计,b是端到端的流设计。其中,a的设计使得当下游节点3因某些情况必须缓存数据暂缓处理时,每个上游节点(1和2)都可以利用其缓存保存数据;而端到端的设计b里,只有节点3的缓存才可以用于保存数据(读者可以从如何实现上想想为什么)。
对流控制感兴趣的读者,可以看这篇文章:Traffic Management For High-Speed Networks。
3.其他核心概念
3.1 EventTime时间模型
Flink有三种时间模型:ProcessingTime,EventTime和IngestionTime。
关于时间模型看这张图: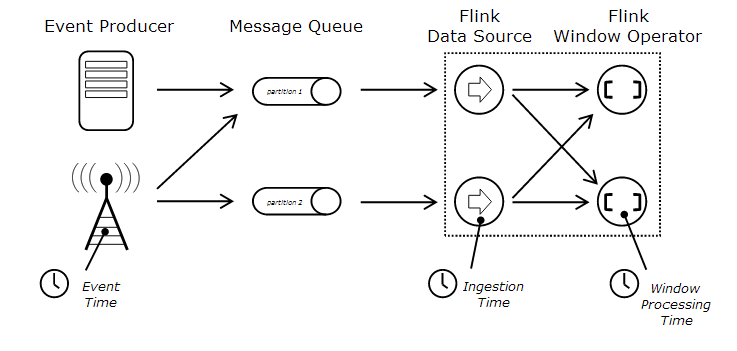
从这张图里可以很清楚的看到三种Time模型的区别。
- EventTime是数据被生产出来的时间,可以是比如传感器发出信号的时间等(此时数据还没有被传输给Flink)。
- IngestionTime是数据进入Flink的时间,也就是从Source进入Flink流的时间(此时数据刚刚被传给Flink)
- ProcessingTime是针对当前算子的系统时间,是指该数据已经进入某个operator时,operator所在系统的当前时间
例如,我在写这段话的时间是2018年5月13日03点47分,但是我引用的这张EventTime的图片,是2015年画出来的,那么这张图的EventTime是2015年,而ProcessingTime是现在。
Flink官网对于时间戳的解释非常详细:点我
Flink对于EventTime模型的实现,依赖的是一种叫做watermark的对象。watermark是携带有时间戳的一个对象,会按照程序的要求被插入到数据流中,用以标志某个事件在该时间发生了。
我再做一点简短的说明,还是以官网的图为例: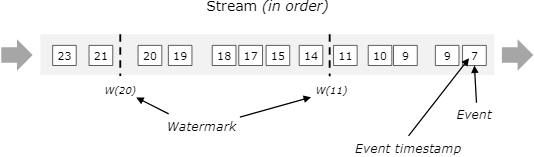
对于有序到来的数据,假设我们在timestamp为11的元素后加入一个watermark,时间记录为11,则下个元素收到该watermark时,认为所有早于11的元素均已到达。这是非常理想的情况。
而在现实生活中,经常会遇到乱序的数据。这时,我们虽然在timestamp为7的元素后就收到了11,但是我们一直等到了收到元素12之后,才插入了watermark为11的元素。与上面的图相比,如果我们仍然在11后就插入11的watermark,那么元素9就会被丢弃,造成数据丢失。而我们在12之后插入watermark11,就保证了9仍然会被下一个operator处理。当然,我们不可能无限制的永远等待迟到元素,所以要在哪个元素后插入11需要根据实际场景权衡。
对于来自多个数据源的watermark,可以看这张图:
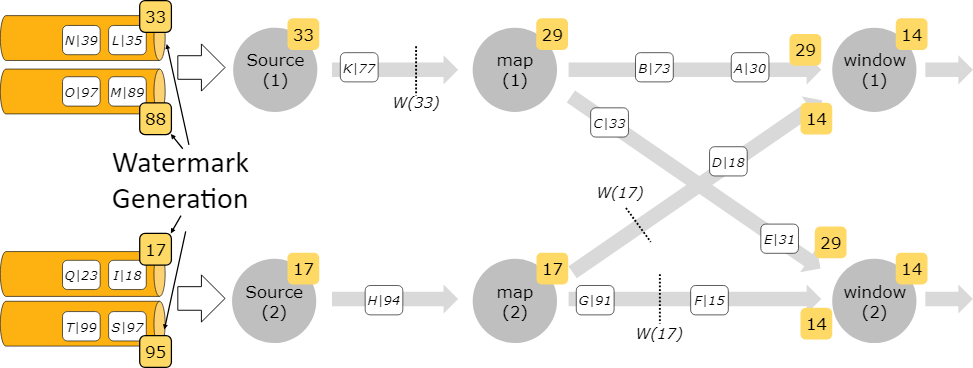
可以看到,当一个operator收到多个watermark时,它遵循最小原则(或者说最早),即算子的当前watermark是流经该算子的最小watermark,以容许来自不同的source的乱序数据到来。
关于事件时间模型,更多内容可以参考Stream 101 和谷歌的这篇论文:Dataflow Model paper
3.2 FLIP-6 部署及处理模型演进
3.2.1 现有模型不足
1.5之前的Flink模型有很多不足,包括:
- 只能静态分配计算资源
- 在YARN上所有的资源分配都是一碗水端平的
- 与Docker/k8s的集成非常之蠢,颇有脱裤子放屁的神韵
- JobManager没有任务调度逻辑
- 任务在YARN上执行结束后web dashboard就不可用
- 集群的session模式和per job模式混淆难以理解
就我个人而言,我觉得Flink有一个这里完全没提到的不足才是最应该修改的:针对任务的完全的资源隔离。尤其是如果用Standalone集群,一个用户的task跑挂了TaskManager,然后拖垮了整个集群的情况简直不要太多。
3.2.2 Cluster Manager的架构
YARN
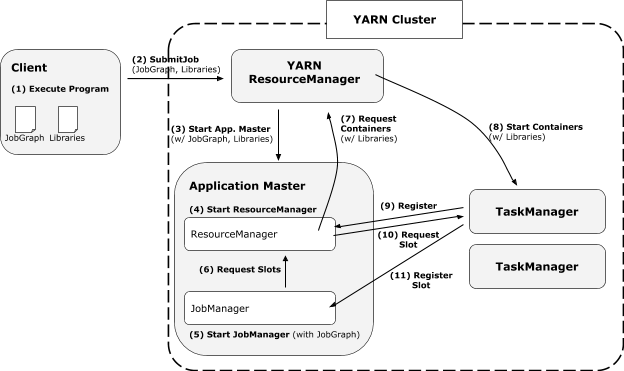
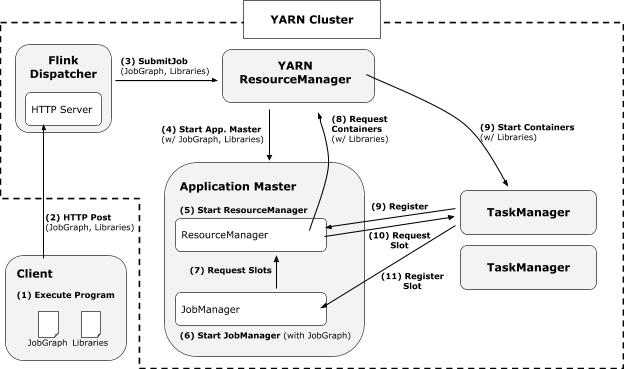
新的基于YARN的架构主要包括不再需要先在容器里启动集群,然后提交任务;用户代码不再使用动态ClassLoader加载;不用的资源可以释放;可以按需分配不同大小的容器等。其执行过程如下:
无Dispatcher时
有Dispatcher时
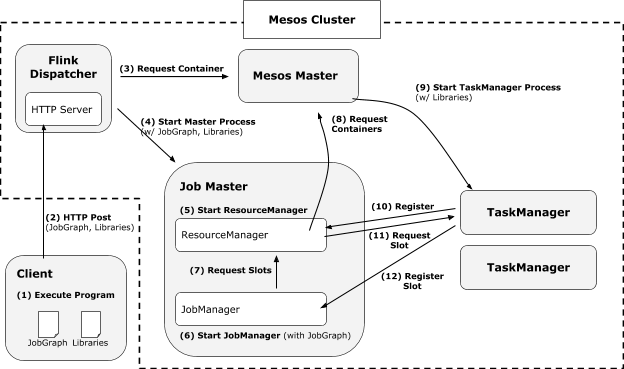
Mesos
与基于YARN的模式很像,但是只有带Dispatcher模式,因为只有这样才能在Mesos集群里跑其RM。
Mesos的Fault Tolerance是类似这样的:
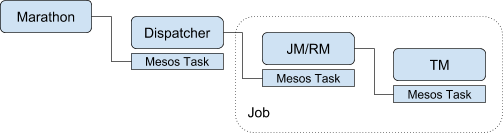
必须用类似Marathon之类的技术保证Dispatcher的HA。
Standalone
其实没啥可说的,把以前的JobManager的职责换成现在的Dispatcher就行了。
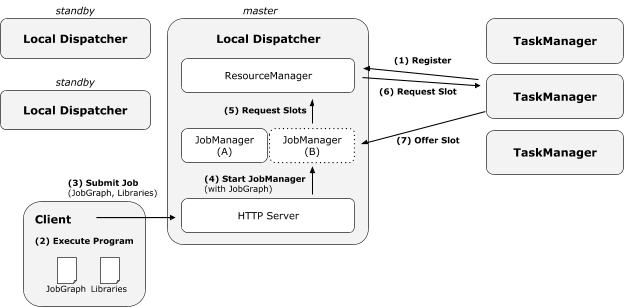
将来可能会实现一个类似于轻量级Yarn的模式。
Docker/k8s
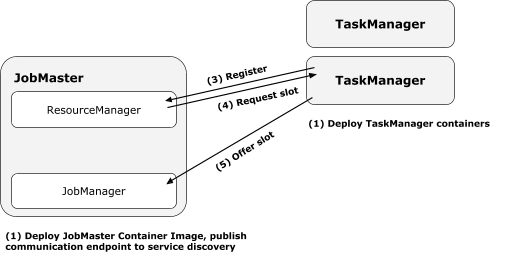
用户定义好容器,至少有一个是job specific的(不然怎么启动任务);还有用于启动TM的,可以不是job specific的。启动过程如下
3.2.3 组件设计及细节
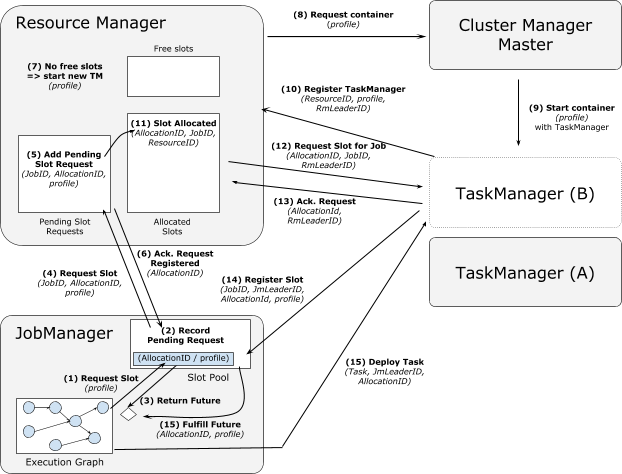
分配slot相关细节
从新的TM取slot过程:
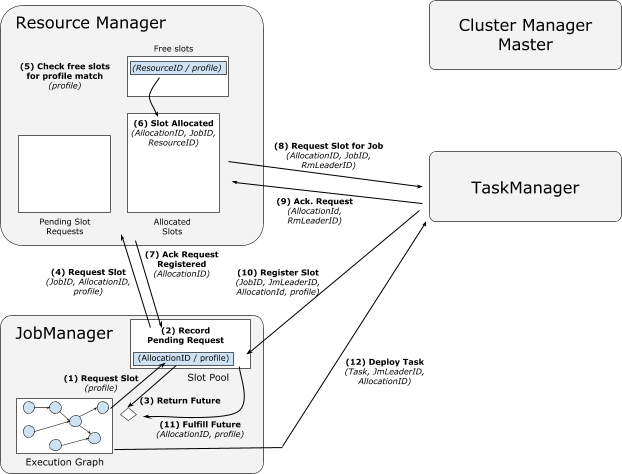
从Cached TM取slot过程:
失败处理
TM失败
TM失败时,RM要能检测到失败,更新自己的状态,发送消息给JM,重启一份TM;JM要能检测到失败,从状态移除失效slot,标记该TM的task为失败,并在没有足够slot继续任务时调整规模;TM自身则要能从Checkpoint恢复RM失败
此时TM要能检测到失败,并准备向新的RM注册自身,并且向新的RM传递自身的资源情况;JM要能检测到失败并且等待新的RM可用,重新请求需要的资源;丢失的数据要能从Container、TM等处恢复。JM失败
TM释放所有task,向新JM注册资源,并且如果不成功,就向RM报告这些资源可用于重分配;RM坐等;JM丢失的数据从持久化存储中获得,已完成的checkpoints从HA恢复,从最近的checkpoint重启task,并申请资源。JM & RM 失败
TM将在一段时间内试图把资源交给新上任的JM,如果失败,则把资源交给新的RMTM & RM失败
JM如果正在申请资源,则要等到新的RM启动后才能获得;JM可能需要调整其规模,因为损失了TM的slot。