前言
Flink是大数据处理领域最近很火的一个开源的分布式、高性能的流式处理框架,其对数据的处理可以达到毫秒级别。本文以一个来自官网的WordCount例子为引,全面阐述Flink的核心架构及执行流程,希望读者可以借此更加深入的理解Flink逻辑。本文跳过了一些基本概念,如果对相关概念感到迷惑,请参考官网文档。
1.从WordCount开始
首先,我们把WordCount的例子再放一遍:
1 | public class SocketTextStreamWordCount { |
首先从命令行中获取socket对端的ip和端口,然后启动一个执行环境,从socket中读取数据,split成单个单词的流,并按单词进行总和的计数,最后打印出来。这个例子相信接触过大数据计算或者函数式编程的人都能看懂,就不过多解释了。
2.Flink执行环境
程序的启动,从这句开始:
1 | final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment() |
这行代码会返回一个可用的执行环境。执行环境是整个Flink程序执行的上下文,记录了相关配置(如并行度等),并提供了一系列方法,如读取输入流的方法,以及真正开始运行整个代码的execute方法等。对于分布式流处理程序来说,我们在代码中定义的flatMap,keyBy等等操作,事实上可以理解为一种声明,告诉整个程序我们采用了什么样的算子,而真正开启计算的代码不在此处。由于我们是在本地运行Flink程序,因此这行代码会返回一个LocalStreamEnvironment,最后我们要调用它的execute方法来开启真正的任务。我们先接着往下看。
3.算子(Operator)的注册
我们以flatMap为例:
1 | public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper) { |
这里面完成了两件事,一是用反射拿到了flatMap算子的输出类型,二是生成了一个Operator。Flink流式计算的核心概念,就是将数据从输入流一个个传递给Operator进行链式处理,最后交给输出流的过程。对数据的每一次处理在逻辑上成为一个Operator,并且为了本地化处理的效率起见,Operator之间也可以串成一个chain一起处理(可以参考责任链模式帮助理解)。下面这张图表明了Flink是如何看待用户的处理流程的:抽象化为一系列Operator,以source开始,以sink结尾,中间的Operator做的操作叫做transform,并且可以把几个操作串在一起执行。
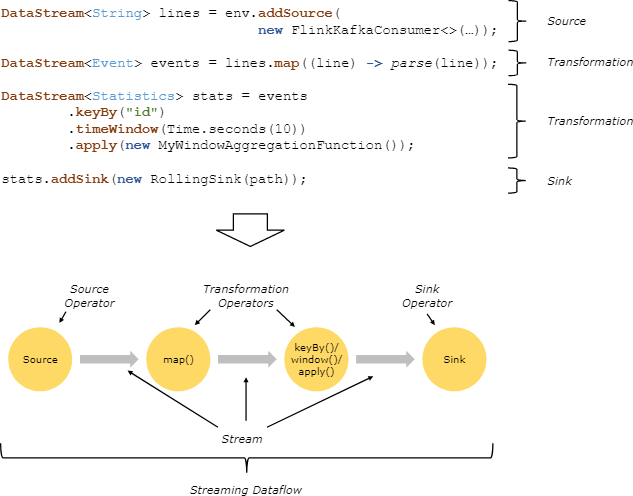
我们也可以更改Flink的设置,要求它不要对某个操作进行chain处理,或者从某个操作开启一个新chain等。
上面代码中的最后一行transform方法的作用是返回一个SingleOutputStreamOperator,它继承了Datastream类并且定义了一些辅助方法,方便对流的操作。在返回之前,transform方法还把它注册到了执行环境中(后面生成执行图的时候还会用到它)。其他的操作,包括keyBy,sum和print,都只是不同的算子,在这里出现都是一样的效果,即生成一个Operator并注册给执行环境用于生成DAG。
4. 程序的执行
程序执行即这行代码
1 | env.execute("Java WordCount from SocketTextStream Example") |
这行代码主要做了以下事情:
- 生成StreamGraph。代表程序的拓扑结构,是从用户代码直接生成的图。
- 生成JobGraph。这个图是要交给Flink去生成task的图。
- 生成一系列配置
- 将JobGraph和配置交给Flink集群去运行。如果不是本地运行的话,还会把jar文件通过网络发给其他节点。
- 以本地模式运行的话,可以看到启动过程,如启动性能度量、web模块、JobManager、ResourceManager、taskManager等等
- 启动任务。值得一提的是在启动任务之前,先启动了一个用户类加载器,这个类加载器可以用来做一些在运行时动态加载类的工作。
4.1远程模式(RemoteEnvironment)的execute方法
远程模式的程序执行更加有趣一点。第一步仍然是获取StreamGraph,然后调用executeRemotely方法进行远程执行。
该方法首先创建一个用户代码加载器
1 | ClassLoader usercodeClassLoader = JobWithJars.buildUserCodeClassLoader(jarFiles, globalClasspaths, getClass().getClassLoader()); |
然后创建一系列配置,交给Client对象。Client这个词有意思,看见它就知道这里绝对是跟远程集群打交道的客户端。
1 | ClusterClient client; |
client的run方法首先生成一个JobGraph,然后将其传递给JobClient。关于Client、JobClient、JobManager到底谁管谁,可以看这张图:
确切的说,JobClient负责以异步的方式和JobManager通信(Actor是scala的异步模块),具体的通信任务由JobClientActor完成。相对应的,JobManager的通信任务也由一个Actor完成。
1 | JobListeningContext jobListeningContext = submitJob( |
可以看到,该方法阻塞在awaitJobResult方法上,并最终返回了一个JobListeningContext,透过这个Context可以得到程序运行的状态和结果。
5.程序启动过程
上面提到,整个程序真正意义上开始执行,是这里:
1 | env.execute("Java WordCount from SocketTextStream Example"); |
远程模式和本地模式有一点不同,我们先按本地模式来调试。
我们跟进源码,(在本地调试模式下)会启动一个miniCluster,然后开始执行代码:
1 | // LocalStreamEnvironment.java |
这个方法里有一部分逻辑是与生成图结构相关的,我们放在第二章里讲;现在我们先接着往里跟:
1 | //MiniCluster.java |
正如我在注释里写的,这一段代码核心逻辑就是调用那个submitJob方法。那么我们再接着看这个方法:
1 | public CompletableFuture<JobSubmissionResult> submitJob(JobGraph jobGraph) { |
这里的Dispatcher是一个接收job,然后指派JobMaster去启动任务的类,我们可以看看它的类结构,有两个实现。在本地环境下启动的是MiniDispatcher,在集群上提交任务时,集群上启动的是StandaloneDispatcher。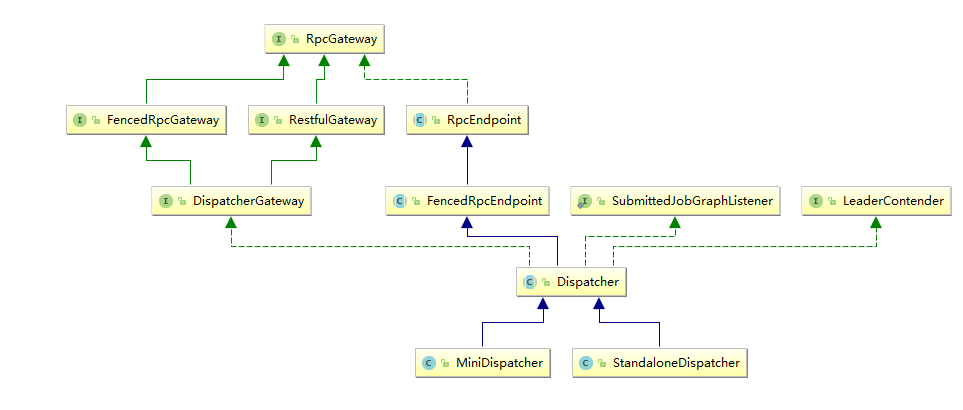
那么这个Dispatcher又做了什么呢?它启动了一个JobManagerRunner(这里我要吐槽Flink的命名,这个东西应该叫做JobMasterRunner才对,Flink里的JobMaster和JobManager不是一个东西),委托JobManagerRunner去启动该Job的JobMaster。我们看一下对应的代码:
1 | //jobManagerRunner.java |
然后,JobMaster经过了一堆方法嵌套之后,执行到了这里:
1 | private void scheduleExecutionGraph() { |
我们知道,Flink的框架里有三层图结构,其中ExecutionGraph就是真正被执行的那一层,所以到这里为止,一个任务从提交到真正执行的流程就走完了,我们再回顾一下(顺便提一下远程提交时的流程区别):
- 客户端代码的execute方法执行;
- 本地环境下,MiniCluster完成了大部分任务,直接把任务委派给了MiniDispatcher;
- 远程环境下,启动了一个RestClusterClient,这个类会以HTTP Rest的方式把用户代码提交到集群上;
- 远程环境下,请求发到集群上之后,必然有个handler去处理,在这里是JobSubmitHandler。这个类接手了请求后,委派StandaloneDispatcher启动job,到这里之后,本地提交和远程提交的逻辑往后又统一了;
- Dispatcher接手job之后,会实例化一个JobManagerRunner,然后用这个runner启动job;
- JobManagerRunner接下来把job交给了JobMaster去处理;
- JobMaster使用ExecutionGraph的方法启动了整个执行图;整个任务就启动起来了。
至此,第一部分就讲完了。