// if we get here, then the user function either exited after being done (finite source) // or the function was canceled or stopped. For the finite source case, we should emit // a final watermark that indicates that we reached the end of event-time if (!isCanceledOrStopped()) { ctx.emitWatermark(Watermark.MAX_WATERMARK); } } finally { // make sure that the context is closed in any case ctx.close(); if (latencyEmitter != null) { latencyEmitter.close(); } } }
publicLatencyMarksEmitter( final ProcessingTimeService processingTimeService, final Output<StreamRecord<OUT>> output, long latencyTrackingInterval, finalint vertexID, finalint subtaskIndex){
latencyMarkTimer = processingTimeService.scheduleAtFixedRate( new ProcessingTimeCallback() { @Override publicvoidonProcessingTime(long timestamp)throws Exception { try { // ProcessingTimeService callbacks are executed under the checkpointing lock output.emitLatencyMarker(new LatencyMarker(timestamp, vertexID, subtaskIndex)); } catch (Throwable t) { // we catch the Throwables here so that we don't trigger the processing // timer services async exception handler LOG.warn("Error while emitting latency marker.", t); } } }, 0L, latencyTrackingInterval); }
publicvoidrun(SourceContext<String> ctx)throws Exception { final StringBuilder buffer = new StringBuilder(); long attempt = 0;
while (isRunning) {
try (Socket socket = new Socket()) { currentSocket = socket;
LOG.info("Connecting to server socket " + hostname + ':' + port); socket.connect(new InetSocketAddress(hostname, port), CONNECTION_TIMEOUT_TIME); BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
char[] cbuf = newchar[8192]; int bytesRead; //核心逻辑就是一直读inputSocket,然后交给collect方法 while (isRunning && (bytesRead = reader.read(cbuf)) != -1) { buffer.append(cbuf, 0, bytesRead); int delimPos; while (buffer.length() >= delimiter.length() && (delimPos = buffer.indexOf(delimiter)) != -1) { String record = buffer.substring(0, delimPos); // truncate trailing carriage return if (delimiter.equals("\n") && record.endsWith("\r")) { record = record.substring(0, record.length() - 1); } //读到数据后,把数据交给collect方法,collect方法负责把数据交到合适的位置(如发布为br变量,或者交给下个operator,或者通过网络发出去) ctx.collect(record); buffer.delete(0, delimPos + delimiter.length()); } } }
// if we dropped out of this loop due to an EOF, sleep and retry if (isRunning) { attempt++; if (maxNumRetries == -1 || attempt < maxNumRetries) { LOG.warn("Lost connection to server socket. Retrying in " + delayBetweenRetries + " msecs..."); Thread.sleep(delayBetweenRetries); } else { // this should probably be here, but some examples expect simple exists of the stream source // throw new EOFException("Reached end of stream and reconnects are not enabled."); break; } } }
// collect trailing data if (buffer.length() > 0) { ctx.collect(buffer.toString()); } }
/** * Processes one element that arrived at this operator. * This method is guaranteed to not be called concurrently with other methods of the operator. */ voidprocessElement(StreamRecord<IN> element)throws Exception;
/** * Processes a {@link Watermark}. * This method is guaranteed to not be called concurrently with other methods of the operator. * * @see org.apache.Flink.streaming.api.watermark.Watermark */ voidprocessWatermark(Watermark mark)throws Exception;
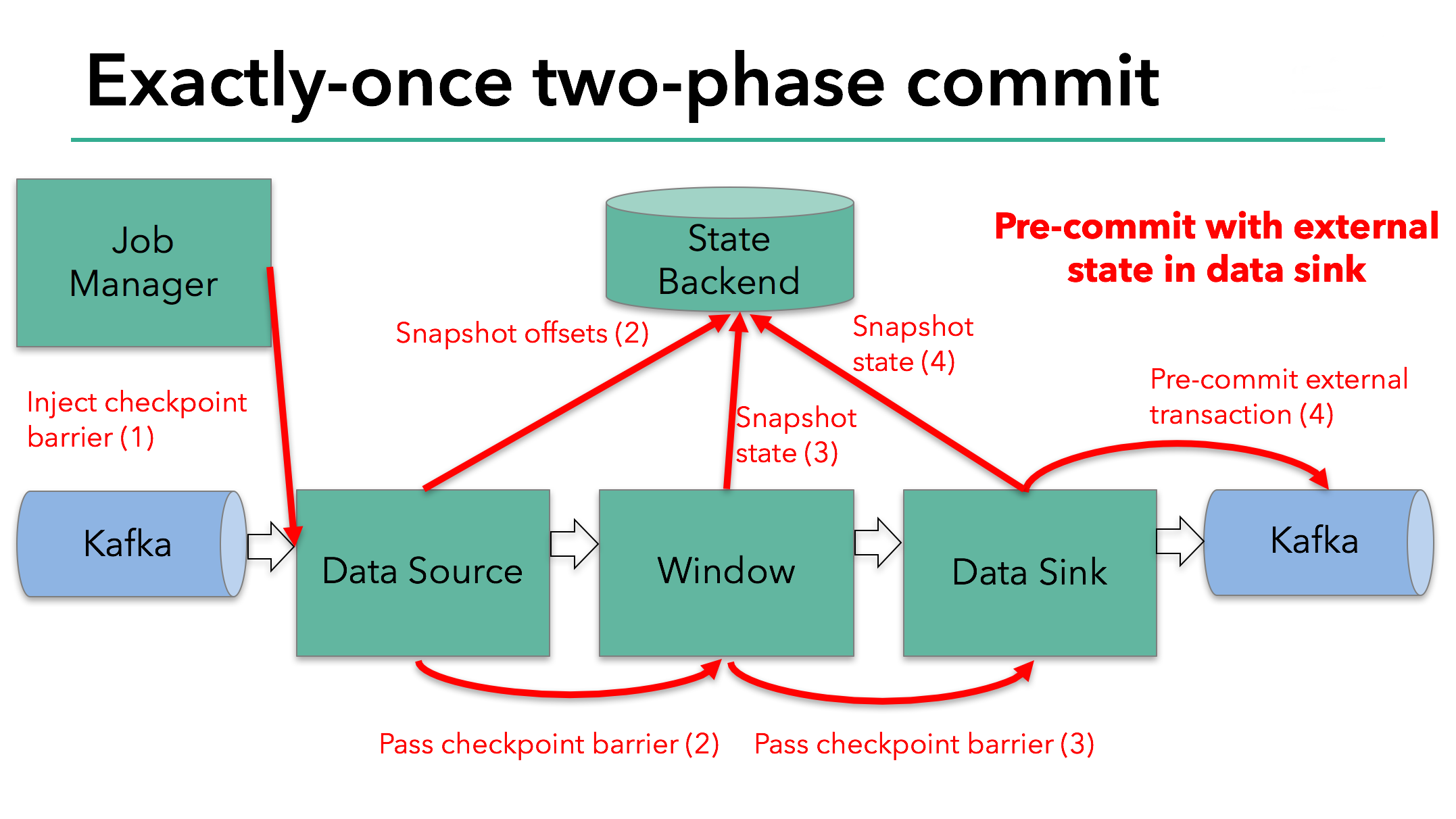
storm的fault tolerant是这样工作的:每一个被storm的operator处理的数据都会向其上一个operator发送一份应答消息,通知其已被下游处理。storm的源operator保存了所有已发送的消息的每一个下游算子的应答消息,当它收到来自sink的应答时,它就知道该消息已经被完整处理,可以移除了。 如果没有收到应答,storm就会重发该消息。显而易见,这是一种at least once的逻辑。另外,这种方式面临着严重的幂等性问题,例如对一个count算子,如果count的下游算子出错,source重发该消息,那么防止该消息被count两遍的逻辑需要程序员自己去实现。最后,这样一种处理方式非常低效,吞吐量很低。
// send the messages to the tasks that trigger their checkpoint for (Execution execution: executions) { execution.triggerCheckpoint(checkpointID, timestamp, checkpointOptions); }
publicvoidtriggerCheckpoint(long checkpointId, long timestamp, CheckpointOptions checkpointOptions){ final LogicalSlot slot = assignedResource;
if (slot != null) { //TaskManagerGateway是用来跟taskManager进行通信的组件 final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway();
taskManagerGateway.triggerCheckpoint(attemptId, getVertex().getJobId(), checkpointId, timestamp, checkpointOptions); } else { LOG.debug("The execution has no slot assigned. This indicates that the execution is " + "no longer running."); } }
publicvoidtriggerCheckpointBarrier( finallong checkpointID, long checkpointTimestamp, final CheckpointOptions checkpointOptions){
......
Runnable runnable = new Runnable() { @Override publicvoidrun(){ // set safety net from the task's context for checkpointing thread LOG.debug("Creating FileSystem stream leak safety net for {}", Thread.currentThread().getName()); FileSystemSafetyNet.setSafetyNetCloseableRegistryForThread(safetyNetCloseableRegistry);
try { boolean success = invokable.triggerCheckpoint(checkpointMetaData, checkpointOptions); if (!success) { checkpointResponder.declineCheckpoint( getJobID(), getExecutionId(), checkpointID, new CheckpointDeclineTaskNotReadyException(taskName)); } }
try { //这里,就是调用StreamOperator进行snapshotState的入口方法 for (StreamOperator<?> op : allOperators) { checkpointStreamOperator(op); }
// we are transferring ownership over snapshotInProgressList for cleanup to the thread, active on submit AsyncCheckpointRunnable asyncCheckpointRunnable = new AsyncCheckpointRunnable( owner, operatorSnapshotsInProgress, checkpointMetaData, checkpointMetrics, startAsyncPartNano);
publicfinalvoidsnapshotState(FunctionSnapshotContext context)throws Exception { if (!running) { LOG.debug("snapshotState() called on closed source"); } else { unionOffsetStates.clear();
final AbstractFetcher<?, ?> fetcher = this.kafkaFetcher; if (fetcher == null) { // the fetcher has not yet been initialized, which means we need to return the // originally restored offsets or the assigned partitions for (Map.Entry<KafkaTopicPartition, Long> subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) { unionOffsetStates.add(Tuple2.of(subscribedPartition.getKey(), subscribedPartition.getValue())); }
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // the map cannot be asynchronously updated, because only one checkpoint call can happen // on this function at a time: either snapshotState() or notifyCheckpointComplete() pendingOffsetsToCommit.put(context.getCheckpointId(), restoredState); } } else { HashMap<KafkaTopicPartition, Long> currentOffsets = fetcher.snapshotCurrentState();
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // the map cannot be asynchronously updated, because only one checkpoint call can happen // on this function at a time: either snapshotState() or notifyCheckpointComplete() pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets); }
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // truncate the map of pending offsets to commit, to prevent infinite growth while (pendingOffsetsToCommit.size() > MAX_NUM_PENDING_CHECKPOINTS) { pendingOffsetsToCommit.remove(0); } } } }
// get the registered operator state infos ... List<RegisteredOperatorBackendStateMetaInfo.Snapshot<?>> operatorMetaInfoSnapshots = new ArrayList<>(registeredOperatorStatesDeepCopies.size());
for (Map.Entry<String, PartitionableListState<?>> entry : registeredOperatorStatesDeepCopies.entrySet()) { operatorMetaInfoSnapshots.add(entry.getValue().getStateMetaInfo().snapshot()); }
// ... write them all in the checkpoint stream ... DataOutputView dov = new DataOutputViewStreamWrapper(localOut);
OperatorBackendSerializationProxy backendSerializationProxy = new OperatorBackendSerializationProxy(operatorMetaInfoSnapshots, broadcastMetaInfoSnapshots);
//BarrierBuffer.getNextNonBlocked方法 elseif (bufferOrEvent.getEvent().getClass() == CheckpointBarrier.class) { if (!endOfStream) { // process barriers only if there is a chance of the checkpoint completing processBarrier((CheckpointBarrier) bufferOrEvent.getEvent(), bufferOrEvent.getChannelIndex()); } } elseif (bufferOrEvent.getEvent().getClass() == CancelCheckpointMarker.class) { processCancellationBarrier((CancelCheckpointMarker) bufferOrEvent.getEvent()); }
privatevoidprocessBarrier(CheckpointBarrier receivedBarrier, int channelIndex)throws Exception { finallong barrierId = receivedBarrier.getId();
// fast path for single channel cases if (totalNumberOfInputChannels == 1) { if (barrierId > currentCheckpointId) { // new checkpoint currentCheckpointId = barrierId; notifyCheckpoint(receivedBarrier); } return; }
// -- general code path for multiple input channels --
if (numBarriersReceived > 0) { // this is only true if some alignment is already progress and was not canceled
if (barrierId == currentCheckpointId) { // regular case onBarrier(channelIndex); } elseif (barrierId > currentCheckpointId) { // we did not complete the current checkpoint, another started before LOG.warn("Received checkpoint barrier for checkpoint {} before completing current checkpoint {}. " + "Skipping current checkpoint.", barrierId, currentCheckpointId);
// let the task know we are not completing this notifyAbort(currentCheckpointId, new CheckpointDeclineSubsumedException(barrierId));
// abort the current checkpoint releaseBlocksAndResetBarriers();
// begin a the new checkpoint beginNewAlignment(barrierId, channelIndex); } else { // ignore trailing barrier from an earlier checkpoint (obsolete now) return; } } elseif (barrierId > currentCheckpointId) { // first barrier of a new checkpoint beginNewAlignment(barrierId, channelIndex); } else { // either the current checkpoint was canceled (numBarriers == 0) or // this barrier is from an old subsumed checkpoint return; }
// check if we have all barriers - since canceled checkpoints always have zero barriers // this can only happen on a non canceled checkpoint if (numBarriersReceived + numClosedChannels == totalNumberOfInputChannels) { // actually trigger checkpoint if (LOG.isDebugEnabled()) { LOG.debug("Received all barriers, triggering checkpoint {} at {}", receivedBarrier.getId(), receivedBarrier.getTimestamp()); }
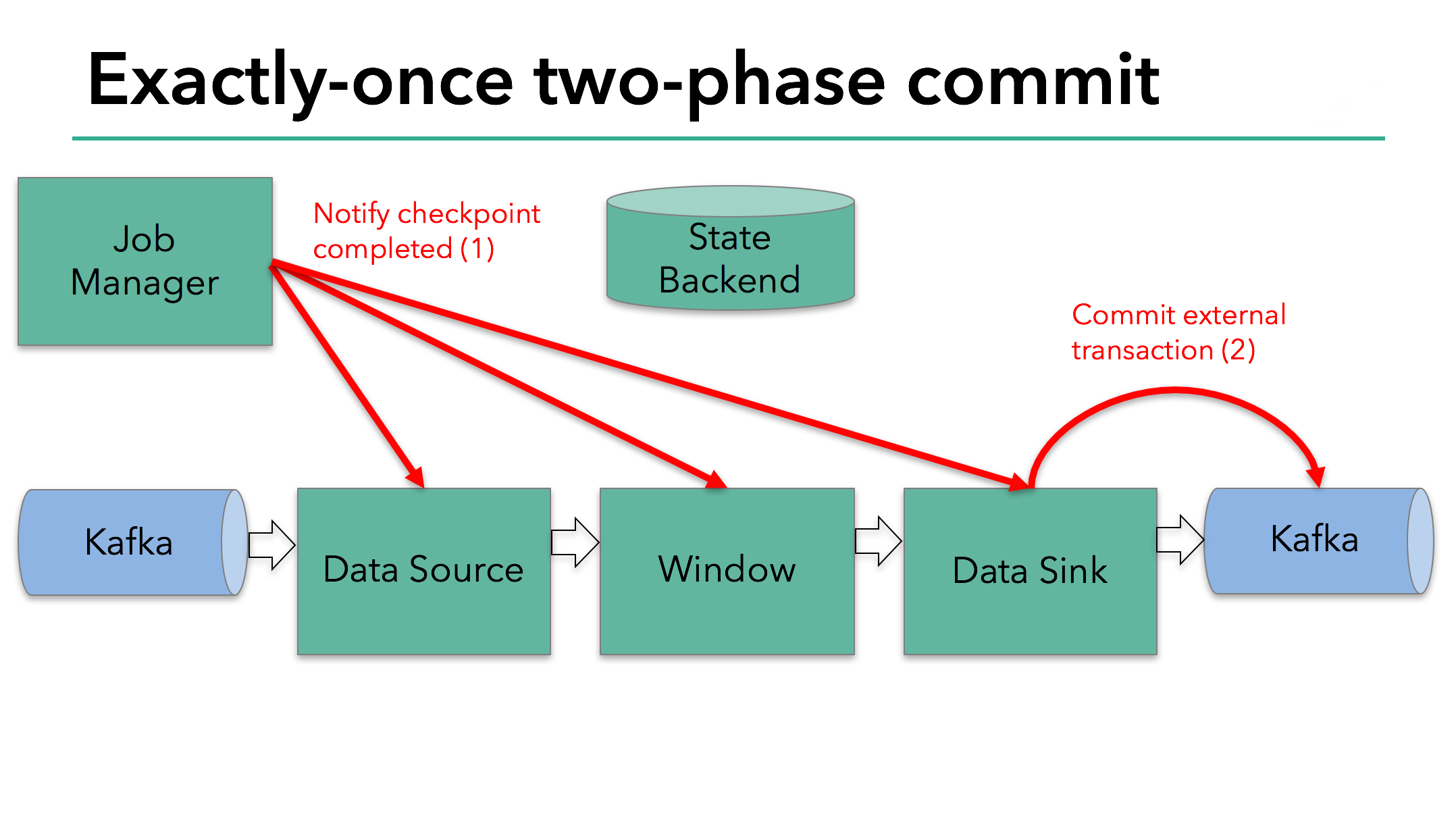
//JobMaster.java publicvoidacknowledgeCheckpoint( final JobID jobID, final ExecutionAttemptID executionAttemptID, finallong checkpointId, final CheckpointMetrics checkpointMetrics, final TaskStateSnapshot checkpointState){
final CheckpointCoordinator checkpointCoordinator = executionGraph.getCheckpointCoordinator(); final AcknowledgeCheckpoint ackMessage = new AcknowledgeCheckpoint( jobID, executionAttemptID, checkpointId, checkpointMetrics, checkpointState);
if (checkpointCoordinator != null) { getRpcService().execute(() -> { try { checkpointCoordinator.receiveAcknowledgeMessage(ackMessage); } catch (Throwable t) { log.warn("Error while processing checkpoint acknowledgement message"); } }); } else { log.error("Received AcknowledgeCheckpoint message for job {} with no CheckpointCoordinator", jobGraph.getJobID()); } }