Redis 分布式路由中间件
入职公司不久、发现各种业务强依赖Redis以至于公司研发了Redis分布式存储路由中间件、经过一段时间的源码学习总结一下。
先来一张大的思维导图(PS:思维导图真的对我们理解总结很有帮助)
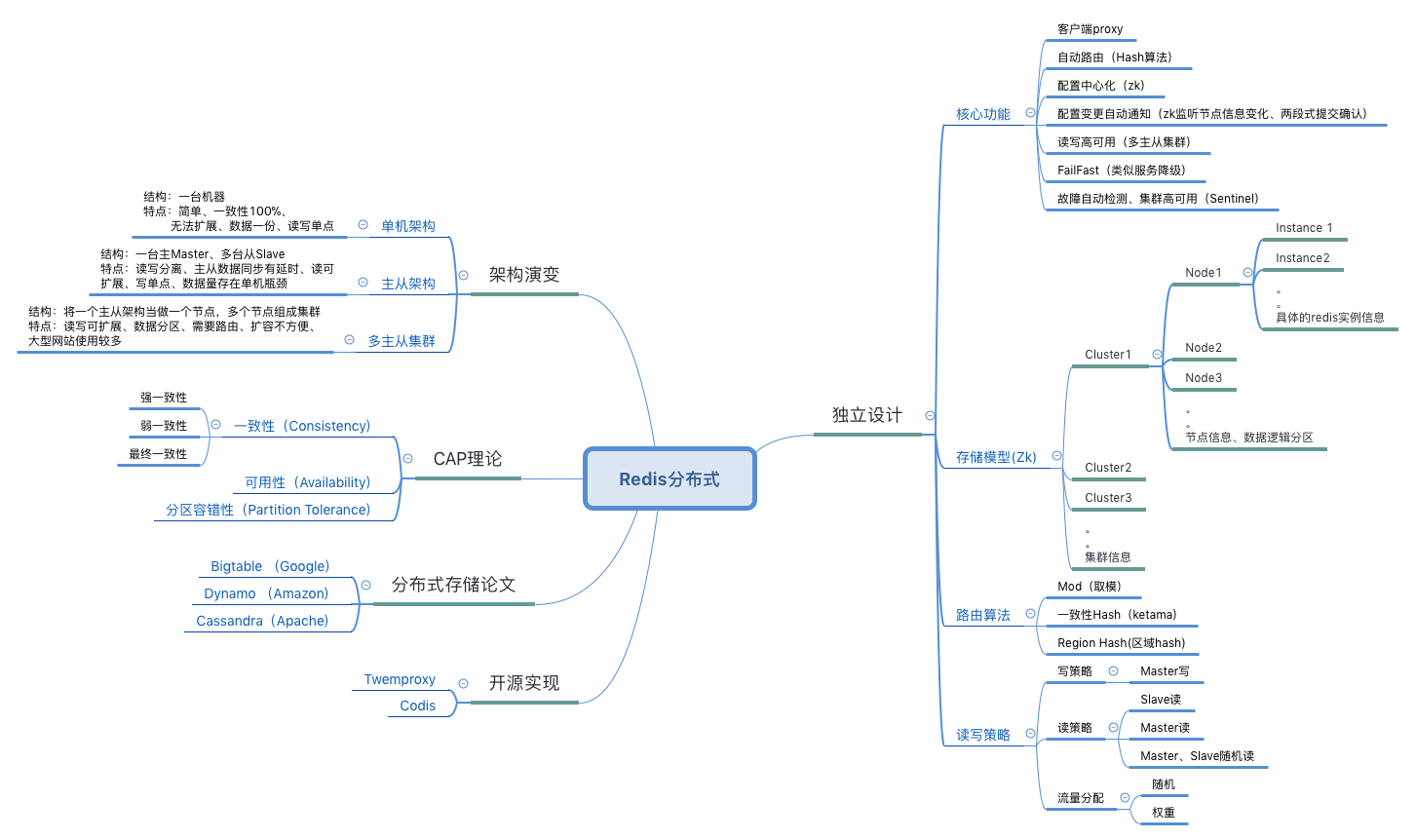
概述
Redis-Store是基于客户端的分布式存储路由中间件。本地从zookeeper配置中拉取和监听Redis配置信息、根据策略自动路由。
节点类型设计
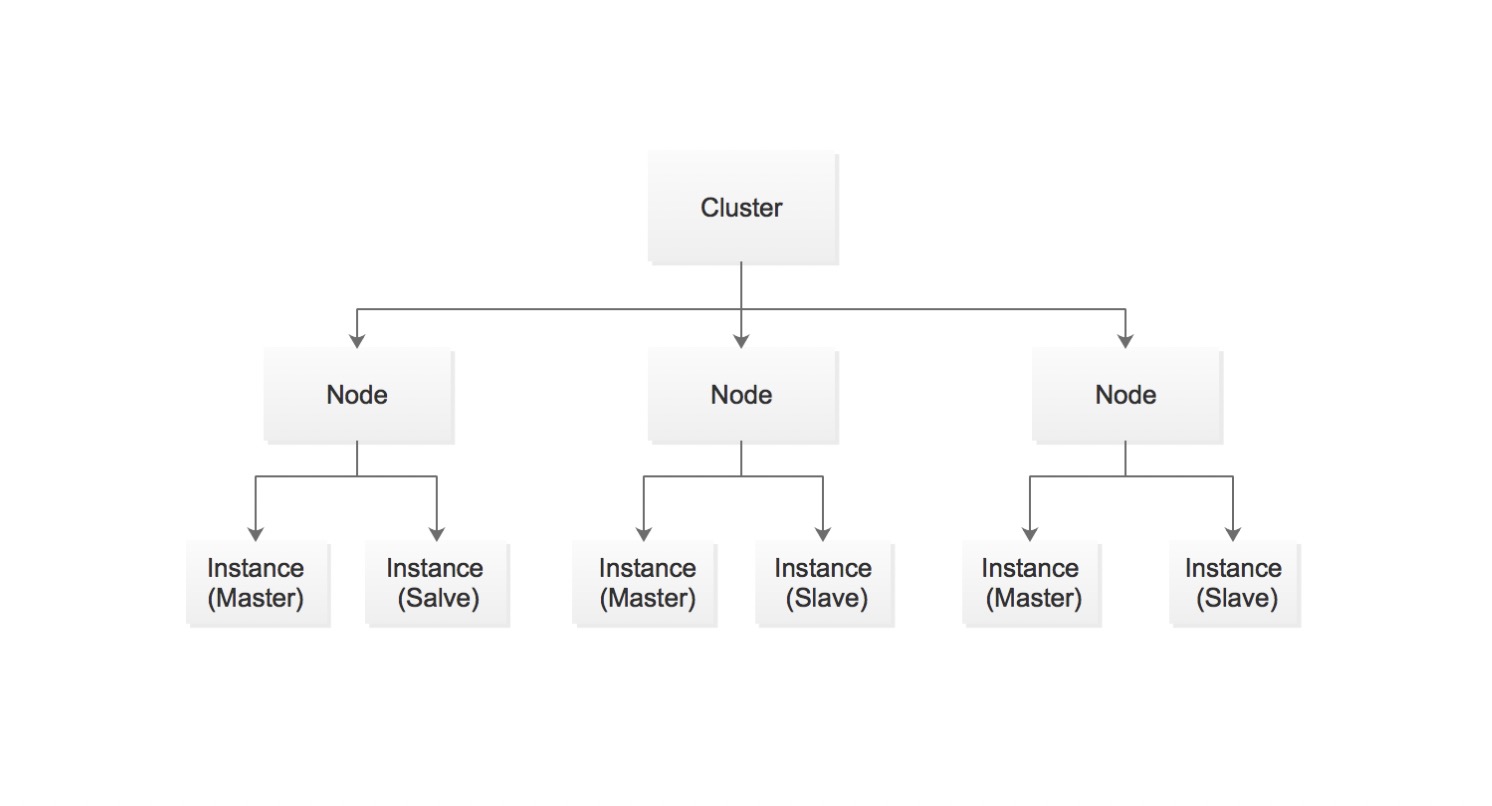
- Cluster: 集群名称(对应业务名称)、每一个业务是一个独立的Cluster结构。zk根节点是[/clusters]。
- Node: 数据的逻辑分区、可以理解为分片。
- Instance:实际的Redis实例、由一小组主从结构构成。
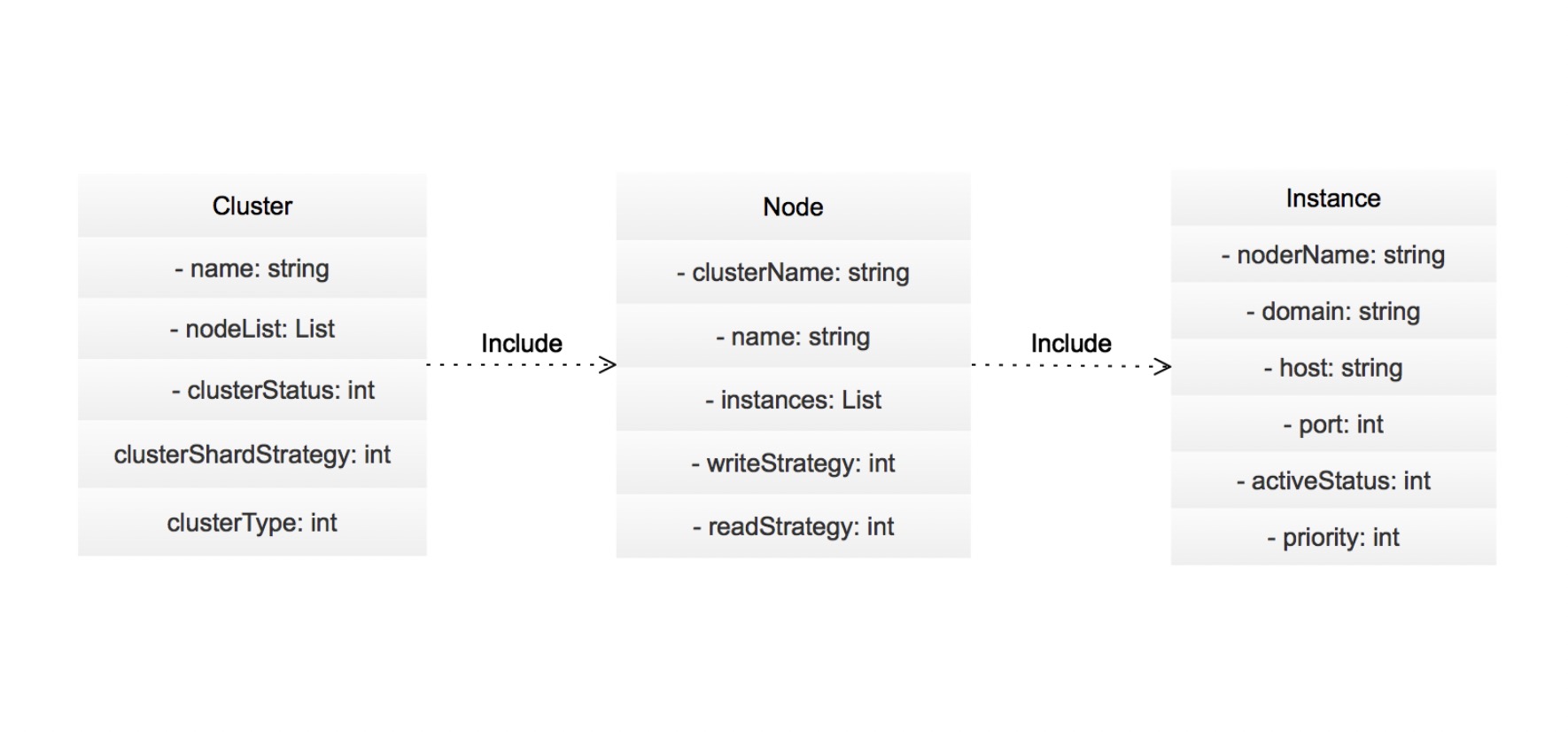
节点数据设计
路由流程设计
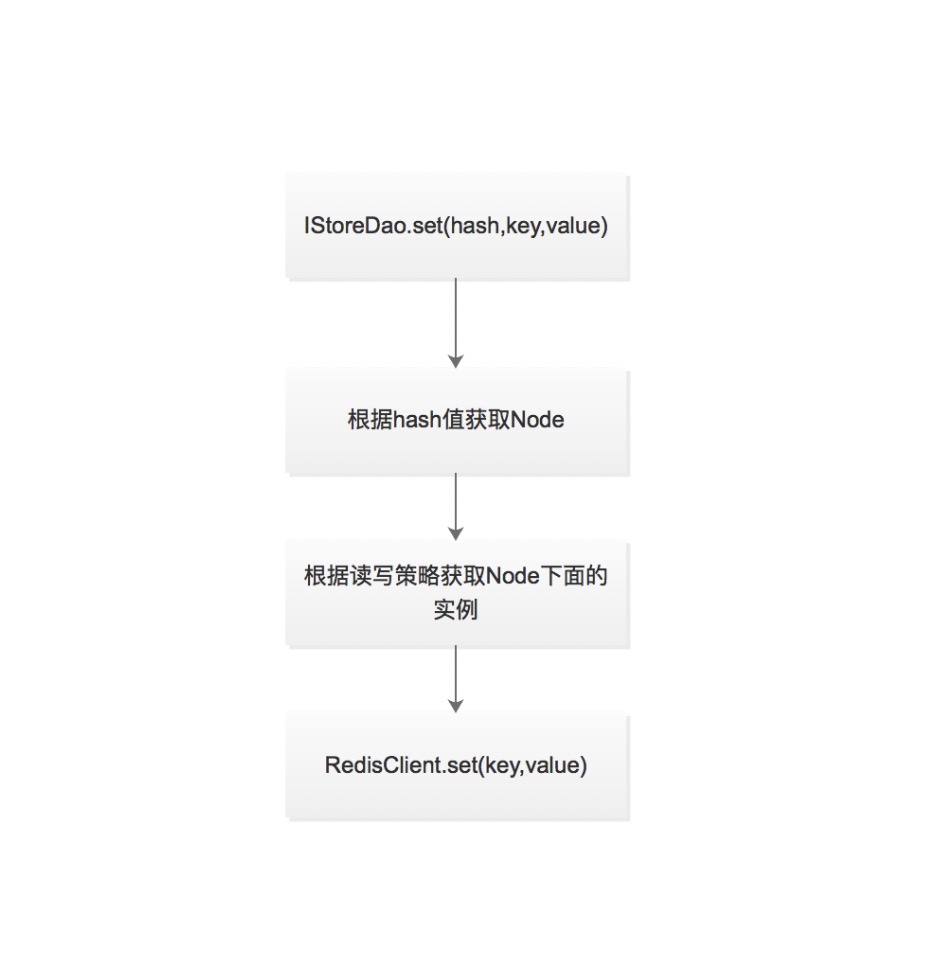
客户端请求的如何落到具体的实例上面。针对原有的Redis客户端、将所有的方法的第一个参数设置为hashKey、后续的处理的根据hash选择Node、根据读写策略获取Master实例还是Slave实例进行具体的读写。比如一个简单的场景,我们初始化了10个分片也就是10个Node节点,每个节点下面一主两从实例。配置Cluster的Hash策略为简单的取模运算。当我们以用户的Id为haskKey进行路由的话,根据用户Id的最后一位数字能确定我们的请求到具体哪个Node,在进行写入的操作的时候请求落到Master实例上面,在进行读操作的时候请求会落到Slave实例上面(当然这是简单的读写策略)。
上面流程中第一步是根据hashKey获取Node。也就是根据hash算法得到我们的请求应该分配到那个分片上面。这个根据不同的业务场景会有不同的设计、有简单的取模哈希、有适应分布式的一致性哈希、有区域哈希、有前缀哈希等等。不能说那种算法最好,使用适合自己业务的。
上面流程中第二步是根据读写策略获取具体的Instance了。一个Node下面是一个小的实例集群,根据自己的业务的需求可以自定义,一般的都是一主两从。如果是写入操作的话获取Master实例、如果是读操作的可以Master读、可以Slave读、可以随机读等等。
集群节点变更设计
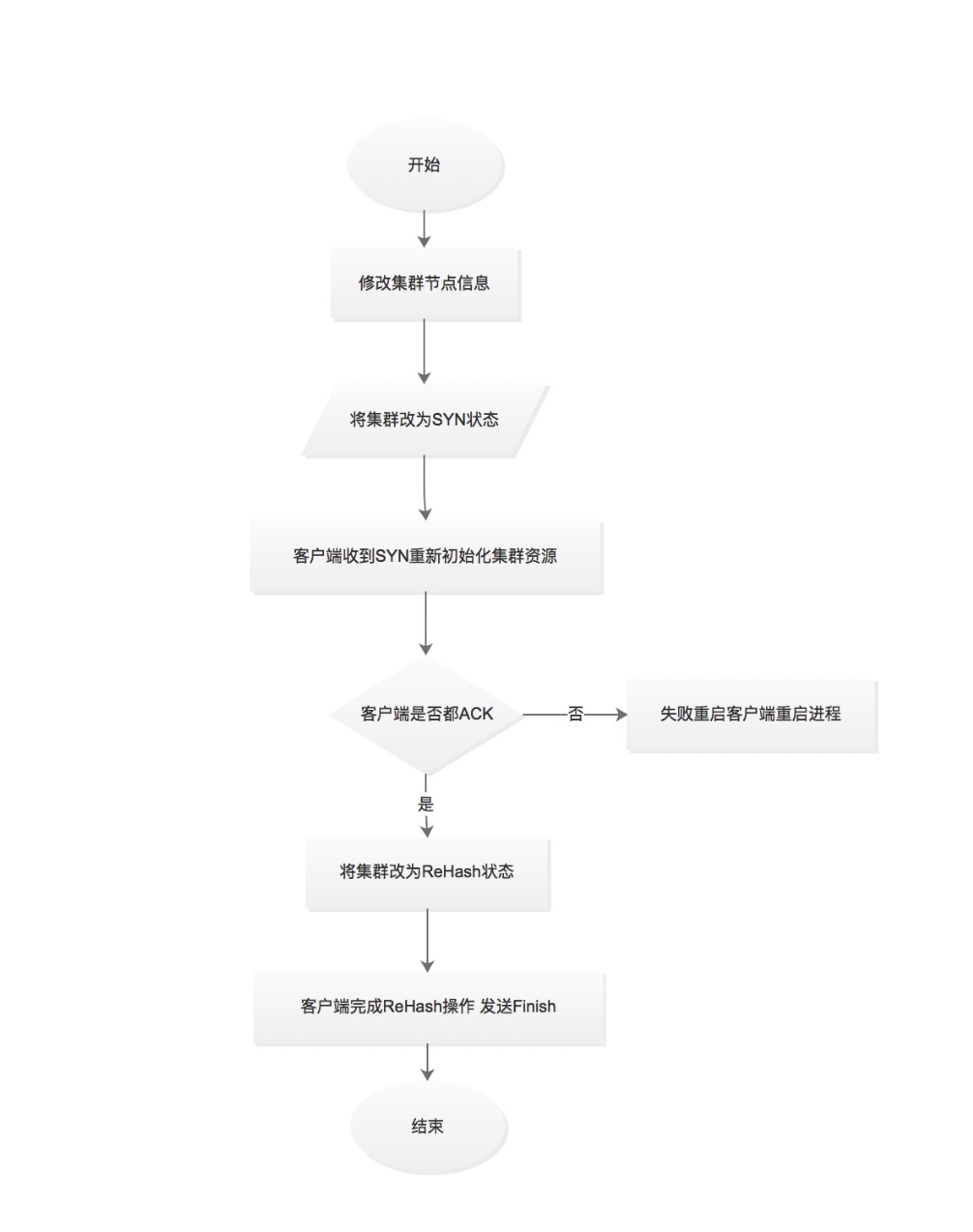
- 集群信息变更两个阶段的提交ACK和FINISH
- 减少集群变更对数据一致性的影响
- 集群状态SYN REHASH NORMAL
扩容设计
- 在业务设计的时候尽量预估好容量
- 如果使用一致性哈希算法直接添加节点
- 对于取模哈希或者区域哈希等其他的算法由于局限性可按倍扩容
- 扩容之后节点的旧数据需要人工处理删除