Spring bean 扫描注解初始化
天和日丽,阳光明媚,小洋接着看Spring bean。上篇文章我们说了,Spring初始化bean的时候有两种方式,一个是在xml里面配置相关内容。一个是用注解扫描。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if(delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for(int i = 0; i < nl.getLength(); ++i) {
Node node = nl.item(i);
if(node instanceof Element) {
Element ele = (Element)node;
if(delegate.isDefaultNamespace(ele)) {
this.parseDefaultElement(ele, delegate);
} else {
delegate.parseCustomElement(ele);
}
}
}
} else {
delegate.parseCustomElement(root);
}
}
|
上次小洋看到这里的时候,进入的是parseDefaultElement这个方法,这个方法是处理默认命名空间的标签的,当我们配置扫描包的时候,比如context:component-scan base-package=”” 这个不是默认命名空间下的标签,他的命名空间是http://www.springframework.org/schema/context。 所以会进入parseCustomElement这个方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
String namespaceUri = this.getNamespaceURI(ele);
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if(handler == null) {
this.error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
} else {
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
}
|
1
2
3
4
5
6
|
public BeanDefinition parse(Element element, ParserContext parserContext) {
return this.findParserForElement(element, parserContext).parse(element, parserContext);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
String localName = parserContext.getDelegate().getLocalName(element);
BeanDefinitionParser parser = (BeanDefinitionParser)this.parsers.get(localName);
if(parser == null) {
parserContext.getReaderContext().fatal("Cannot locate BeanDefinitionParser for element [" + localName + "]", element);
}
return parser;
}
|
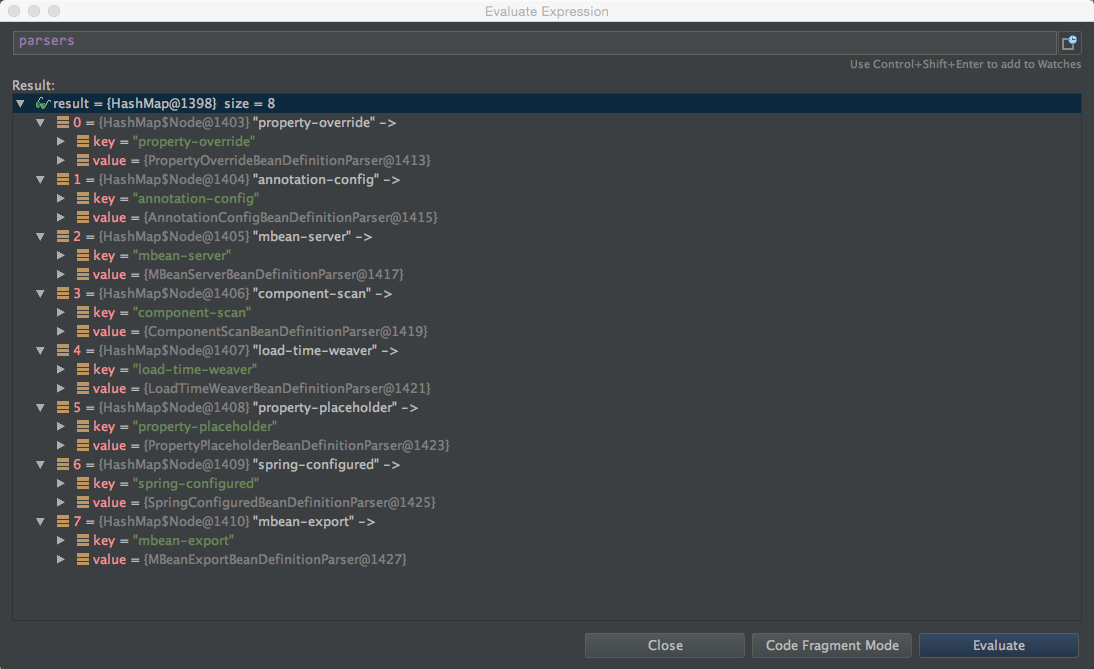
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute("base-package");
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage, ",; \t\n");
ClassPathBeanDefinitionScanner scanner = this.configureScanner(parserContext, element);
Set beanDefinitions = scanner.doScan(basePackages);
this.registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
LinkedHashSet beanDefinitions = new LinkedHashSet();
String[] var3 = basePackages;
int var4 = basePackages.length;
for(int var5 = 0; var5 < var4; ++var5) {
String basePackage = var3[var5];
Set candidates = this.findCandidateComponents(basePackage);
Iterator var8 = candidates.iterator();
while(var8.hasNext()) {
BeanDefinition candidate = (BeanDefinition)var8.next();
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if(candidate instanceof AbstractBeanDefinition) {
this.postProcessBeanDefinition((AbstractBeanDefinition)candidate, beanName);
}
if(candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition)candidate);
}
if(this.checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
this.registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
LinkedHashSet candidates = new LinkedHashSet();
try {
String ex = "classpath*:" + this.resolveBasePackage(basePackage) + "/" + this.resourcePattern;
Resource[] resources = this.resourcePatternResolver.getResources(ex);
boolean traceEnabled = this.logger.isTraceEnabled();
boolean debugEnabled = this.logger.isDebugEnabled();
Resource[] var7 = resources;
int var8 = resources.length;
for(int var9 = 0; var9 < var8; ++var9) {
Resource resource = var7[var9];
if(traceEnabled) {
this.logger.trace("Scanning " + resource);
}
if(resource.isReadable()) {
try {
MetadataReader ex1 = this.metadataReaderFactory.getMetadataReader(resource);
if(this.isCandidateComponent(ex1)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(ex1);
sbd.setResource(resource);
sbd.setSource(resource);
if(this.isCandidateComponent((AnnotatedBeanDefinition)sbd)) {
if(debugEnabled) {
this.logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
} else if(debugEnabled) {
this.logger.debug("Ignored because not a concrete top-level class: " + resource);
}
} else if(traceEnabled) {
this.logger.trace("Ignored because not matching any filter: " + resource);
}
} catch (Throwable var13) {
throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, var13);
}
} else if(traceEnabled) {
this.logger.trace("Ignored because not readable: " + resource);
}
}
return candidates;
} catch (IOException var14) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", var14);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
protected Set<Resource> doFindAllClassPathResources(String path) throws IOException {
LinkedHashSet result = new LinkedHashSet(16);
ClassLoader cl = this.getClassLoader();
Enumeration resourceUrls = cl != null?cl.getResources(path):ClassLoader.getSystemResources(path);
while(resourceUrls.hasMoreElements()) {
URL url = (URL)resourceUrls.nextElement();
result.add(this.convertClassLoaderURL(url));
}
if("".equals(path)) {
this.addAllClassLoaderJarRoots(cl, result);
}
return result;
}
|
小洋这就看完了处理非默认命名空间的元素解析,这里具体用component-scan这个标签来举例说的,Spring针对不同的标签,会用具体的对象去处理解析,改天再去看看其他标签的解析。小洋这里要嘱咐一下,这里我们不管是配置的bean还是扫描的bean,现在在Spring里面就只是一个java对象的数据结构BeanDefinition,并没有实例化。
笨蛋自以为聪明,聪明人才知道自己是笨蛋。
—— 莎士比亚